擷取2020年校園空品資料
-
目前Google Colab程式已安裝 pandas, matplotlib, numpy, seaborn, statsmodels, warnings 等套件,然而,我們還需另外自行安裝兩個未預先安裝好的套件:kats 和 calplot,安裝方式如下:
!pip install --upgrade pip # Kats !pip install kats ax-platform statsmodels # calplot !pip install calplot !pip install pmdarima待安裝完畢後,使用下列的指令來行匯入相關的套件,以完成本單元的準備工作:
import warnings import calplot import pandas as pd import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import statsmodels.api as sm import os, zipfile import pmdarima as pm from datetime import datetime, timedelta from dateutil import parser as datetime_parser from statsmodels.tsa.stattools import adfuller, kpss from statsmodels.tsa.seasonal import seasonal_decompose from kats.detectors.outlier import OutlierDetector from kats.detectors.cusum_detection import CUSUMDetector from kats.consts import TimeSeriesData, TimeSeriesIterator from IPython.core.pylabtools import figsize把2020年的歷史數據擷取下來,解壓縮後,只取用某一台機器所發出的資料,然後針對這台機器的資料進行數據分析。
!mkdir Air CSV_Air !wget -O Air/2020.zip "https://history.colife.org.tw/?r=/download&path=L%2Bepuuawo%2BWTgeizqi%2FkuK3noJTpmaJf5qCh5ZyS56m65ZOB5b6u5Z6L5oSf5ris5ZmoLzIwMjAuemlw" #開始進行解壓縮 folder = 'Air' extension_zip = '.zip' extension_csv = '.csv' for subfolder in os.listdir(folder): path = f'{folder}/{subfolder}' if os.path.isdir(path): for item in os.listdir(path): if item.endswith(extension_zip): file_name = f'{path}/{item}' zip_ref = zipfile.ZipFile(file_name) zip_ref.extractall(path) zip_ref.close() for item in os.listdir(path): path2 = f'{path}/{item}' if os.path.isdir(path2): for it in os.listdir(path2): if it.endswith(extension_zip): file_name = f'{path2}/{it}' zip_ref = zipfile.ZipFile(file_name) zip_ref.extractall('CSV_Air') # decide path zip_ref.close() elif item.endswith(extension_csv): os.rename(path2, f'CSV_Air/{item}')folder = 'CSV_Air' extension_csv = '.csv' id = '74DA38F208E2' air = pd.DataFrame() for item in os.listdir(folder): file_name = f'{folder}/{item}' df = pd.read_csv(file_name) if 'pm25' in list(df.columns): df.rename({'pm25':'PM25'}, axis=1, inplace=True) filtered = df.query(f'device_id==@id') air = pd.concat([air, filtered], ignore_index=True) air.dropna(subset=['timestamp'], inplace=True) for i, row in air.iterrows(): aware = datetime_parser.parse(str(row['timestamp'])) naive = aware.replace(tzinfo=None) air.at[i, 'timestamp'] = naive air.set_index('timestamp', inplace=True) !rm -rf Air CSV_Airair.drop(columns=['device_id', 'SiteName'], inplace=True) air.sort_values(by='timestamp', inplace=True) air.info() print(air.head())plt.figure(figsize=(15, 10), dpi=60) plt.plot(air[:]["PM25"]) plt.xlabel("Date") plt.ylabel("PM2.5") plt.title("PM2.5 Time Series Plot") plt.tight_layout() plt.show()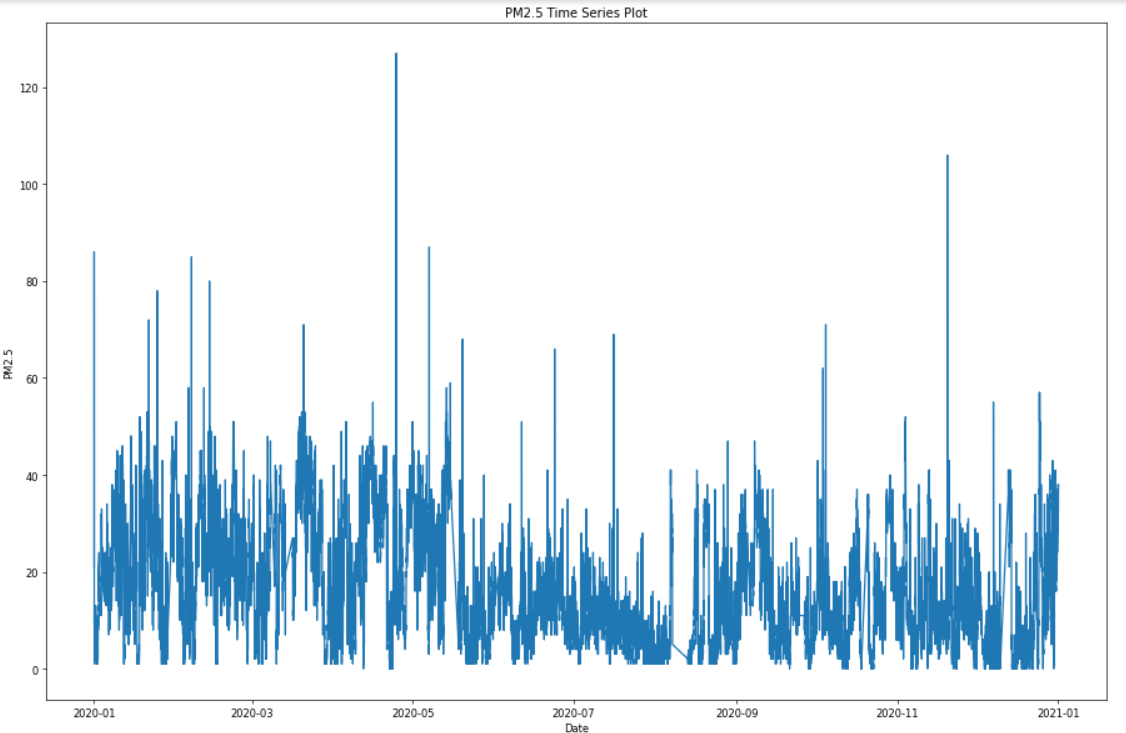
air_hour = air.resample('H').mean() #每小時的平均 air_day = air.resample('D').mean() #每日的平均 air_month = air.resample('M').mean() #每月的平均 print(air_hour.head()) print(air_day.head()) print(air_month.head())# cmap: 設定呈現的顏色色盤 (https://matplotlib.org/stable/gallery/color/colormap_reference.html) # textformat: 設定圖中數字呈現的樣式 pl1 = calplot.calplot(data = air_day['PM25'], cmap = 'GnBu', textformat = '{:.0f}', figsize = (24, 12), suptitle = "PM25 by Month and Year")